


MovieMate
Building a Custom Movie Recommendation Engine That Runs Right in Your Terminal


Introduction
Have you ever wondered how Amazon knows what products you're likely to want, or how Netflix figures out the movies you've been dying to watch? This fun project will give you a simplistic and realistic first-hand experience of the world of recommendation algorithms. As a bonus, you'll get to see how they work under the hood.
Last month, I took a refresher python course. I reviewed the fundamentals of the language and got to also learn a couple of new stuff. What better way to internalize concepts learnt and showcase my knowledge than projects? So I set out to build one.
My interest in AI has spanned a few years, and although, my knowledge of the field is merely superficial, I do understand the role AI system play in prediction, forecasting, pattern detection and enhanced and personalized user experience. For instance, giants such as Netflix, Amazon etc run complex ML models that make personalized recommendations for their users. I set out to model these systems at a less complex and reduced level. So, MovieMate came to life.
Overview
Project Description
MovieMate is an interactive and immersive command-line text-based video streaming platform. It offers users a novel yet simplistic simulated experience watching movies in the command line. The platform has a custom-built adaptive and intuitive recommendation engine that makes personalized movie recommendations to the users.
Technical Composition and Requirements
I developed the project using python programming language and implemented the Object Oriented Programming (OOP) paradigm.OOP proved to be a good fit as it allowed me, using class inheritance, to write modular codes and encapsulate the features of the project into manageable and scalable bits.
Simple-colors is the only external literary I utilized in the project. It provided colourful outputs in the terminal. Since we are usually fascinated by beautiful colour combinations, I implemented it to improve the user experience. I also utilized a virtual environment to manage the project dependencies.
Project Structure
├── database/
│ └── movie_database.json
├── packages/
│ ├── engine/
│ │ └── main.py
│ ├── interface/
│ │ └── main.py
│ └── movie/
│ ├── data.py
│ ├── main.py
│ ├── search.py
│ └── watch.py
├── main.py
├── .gitignore
├── LICENSE
├── README.md
├── requirements.txt
├── setup.py
The above is the folder structure of the project. Brief details on the main files and folders are given below.
database: this folder contains the movie database
packages: this folder contains the codes for the three components of the project; engine, interface and movie.
main.js: this is the entry point into the project
requirements.txt: this file contains external libraries and their version
User Walkthrough
Here, I will give a short description and guide on how to use and navigate the app.
On loading the app, a welcome message is displayed. The user is then prompted to enter the desired menu mode from a list of menu options. The menu modes are: watch(w), home(h), search(s), and recommend(r).

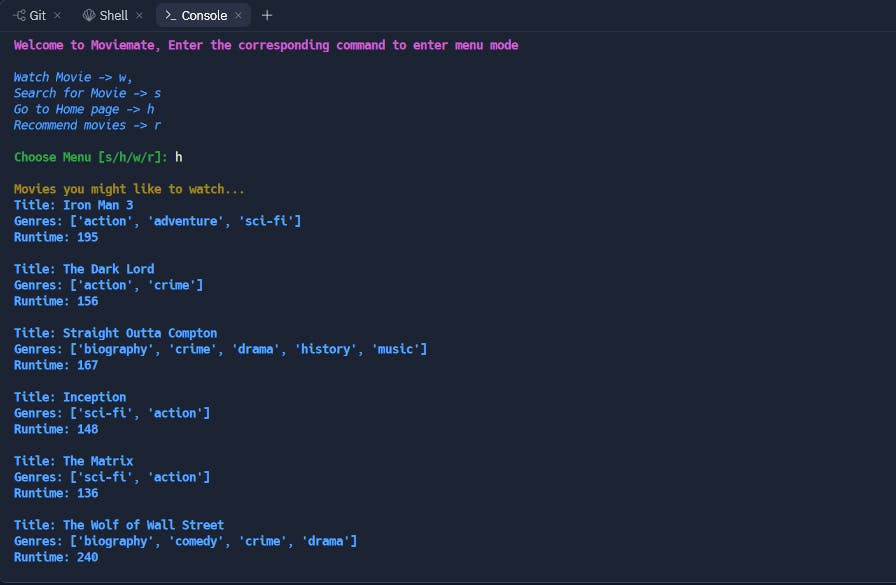
Home mode
Just like the homepage of youtube and other similar platforms, a list of randomly selected movies is displayed to the user.
Watch Mode
This mode allows users to watch any desired movie. The user is prompted to enter the title of the desired movie, after which the watch simulation is run.

To give the user a realistic watching experience, watchtime (in minutes but scaled down to seconds) is read gradually for the actual duration of the movie and displayed as the movie progress. Should the user lose interest in the movie, he is prompted to exit the watch console at every 10 minutes interval.

The watch time on exit together with the movie details is saved in the watch history.
Search Mode
The user can search the database for movies. The search result contains all similar movies as specified in the search query.

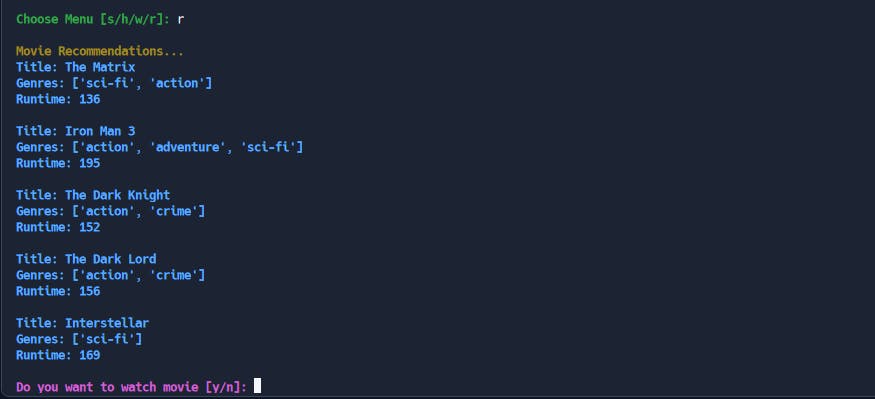
Recommend Mode
In this mode, the engine runs and makes personalized movie recommendations to the user based on watch history. I explain in detail how the engine works in the next section.
The Engine
Here, I give a full and detailed rundown of how the recommendation engine works. The engine is a carefully modelled feature of MovieMate, allowing it to give personalized recommendations to users. The engine is adaptive and comprehensive. It adapts to the changing behavior of the user as reflected in the watch history. And it is comprehensive as it considers all genres a particular movie belongs to.
It works like a Machine Learning model, making predictions of movies the user might be interested in based on two important parameters: the genres and the watchtime.
Program Flow
The Engine class has four methods: recommend_movies, get_recommendation, get_watch_time_ratio, get_movie_similarity
# recommend_movies method
num_recommendations = 5
all_movies = self.all_movies
watched_movies = self.watched_movies
...
...
When the recommend_movies method is called, all_movies and watched_movies variables are initialized. They contain the details of all movies on the database and those currently in the user watch history respectively.
'''
DEMO
# all movies
[
{'title': 'The Matrix', 'genres': ['sci-fi', 'action'], 'runtime': 136},
{'title': 'Inception', 'genres': ['sci-fi', 'adventure', 'action'], 'runtime': 148},
{'title': 'Black Swan', 'genres': ['drama', 'thriller', 'action'], 'runtime': 108},
{'title': "The King's Speech", 'genres': ['drama', 'history'], 'runtime': 118}
]
# watched movies
[
{'title': 'Inception', 'genres': ['sci-fi', 'adventure', 'action'], 'runtime': 148, 'watchtime': 110},
{'title': 'Black Swan', 'genres': ['drama', 'thriller', 'action'], 'runtime': 108, 'watchtime': 80}
]
'''
A similarity score is calculated based on a one-on-one comparison with the movies in the watch history for all the movies on the database not watched yet by the user. Two parameters are considered to calculate a similarity score: genres and watchtime.
For the first parameter, the genre similarity score reflects the genres common to both movies being compared. The second parameter is normalized to eliminate the inherent bias as a result of the varying length of the movies’ runtime. It is normalized as the watchtime/runtime ratio to give a value that ranges between 0 and 1.
# get_watch_time_ratiom method
def get_watch_time_ratio(self, movie):
ratio = movie["watchtime"] / movie["runtime"]
return ratio
A single score is calculated as the sum of the scores for the two parameters.
# get_movie_similarity method
def get_movie_similarity(self, movie1, movie2):
genre_similarity = len(set(movie1["genres"]) & set(movie2["genres"]))
ratio_similarity = self.get_watch_time_ratio(movie2)
similarity = genre_similarity + ratio_similarity
return similarity
A total score is then calculated as the sum of the score for each comparison.
# recommend_movies method
...
similarity_scores = []
for movie in all_movies:
if movie["title"] in [movie["title"] for movie in watched_movies ]:
continue
score = sum([self.get_movie_similarity(movie, watched) for watched in watched_movies])
similarity_scores.append((movie, score))
...
'''
THE ENGINE PROCESSES UNDER THE HOOD
COMPARING Inception WITH The Matrix
Genre similarity: 2
Ratio_similarity: 0.743243
Similarity score: 2.743243
COMPARING Black Swan WITH The Matrix
Genre similarity: 1
Ratio_similarity: 0.7407407
Similarity score: 1.7407407
Movie: The Matrix || Total Similarity score: 4.483983
.........
.........
COMPARING Inception WITH The King's Speech
Genre similarity: 0
Ratio_similarity: 0.743243
Similarity score: 0.743243
COMPARING Black Swan WITH The King's Speech
Genre similarity: 1
Ratio_similarity: 0.740740
Similarity score: 1.740740
Movie: The King's Speech || Total Similarity score: 2.483983
'''
Movies with the highest score are recommended.
# get_recommendation method
def get_recommendation(self):
recommendation = self.recommend_movies()
recommendation = [self.formatter(movie) for movie in recommendation]
print(yellow("\nMovie Recommendations...", "bold"))
print(*recommendation, sep="\n\n")
self.want_to_watch()
'''
OUTPUT
Movie Recommendations...
1. Title: The Matrix
Genres: ['sci-fi', 'action']
Runtime: 136
2. Title: The King's Speech
Genres: ['drama', 'history']
Runtime: 118
'''
It can be observed that the order of the recommended movies indicates that the Engine made a good inference based on the user's watch history.
Engine Full Code
Below is the full commented code for the recommendation engine.
# Engine class
from dataclasses import dataclass
import random
from simple_colors import *
@dataclass
class Engine:
# Calculate the watch/runtime ratio for the watched movies.
# This ratio is an important parameter for the recommendation algorithm
def get_watch_time_ratio(self, movie):
ratio = movie["watchtime"] / movie["runtime"]
return ratio
# Calculate similarity score for each yet to be watched movie as
# compared against all movies in the user watch history
def get_movie_similarity(self, movie1, movie2):
# Calculate similarity based on genre match
genre_similarity = len(set(movie1["genres"]) & set(movie2["genres"]))
# Calculate similarity based on watch time/runtime ratio
ratio_similarity = self.get_watch_time_ratio(movie2)
# Combine the similarities into a single value
similarity = genre_similarity + ratio_similarity
return similarity
# Recommends the top 5 movies with the highest similarity score
def recommend_movies(self):
num_recommendations = 5
all_movies = self.all_movies
watched_movies = self.watched_movies
# Calculate similarity between each movie and the previously watched movies
similarity_scores = []
for movie in all_movies:
# skip movies already watched
if movie["title"] in [movie["title"] for movie in watched_movies ]:
continue
score = sum([self.get_movie_similarity(movie, watched) for watched in watched_movies])
similarity_scores.append((movie, score))
# Sort movies by similarity
similarity_scores.sort(key=lambda x: x[1], reverse=True)
# Return the top n=5 movies
return [movie for movie, _ in similarity_scores[:num_recommendations]]
def get_recommendation(self):
recommendation = self.recommend_movies()
recommendation = [self.formatter(movie) for movie in recommendation]
print(yellow("\nMovie Recommendations...", "bold"))
print(*recommendation, sep="\n\n")
self.want_to_watch()
Conclusion
And that's the whole MovieMate explained in an article. Feel free to check out the repository, fork and improve upon the codebase. It's open source by the way.
Should you choose to save yourself the hassle of setting up a local environment to test it, you can still play around with it here.
Thanks for reading.